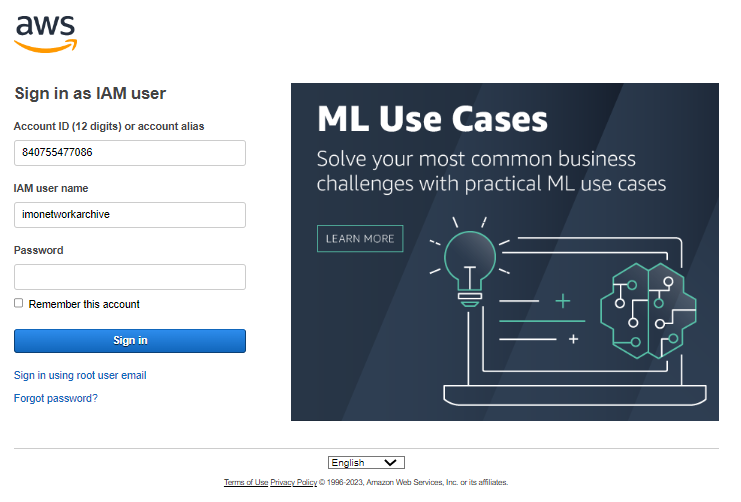
You are then using the S3 console to navigate though the archive. The top level structure are the years as described in the archive structure.
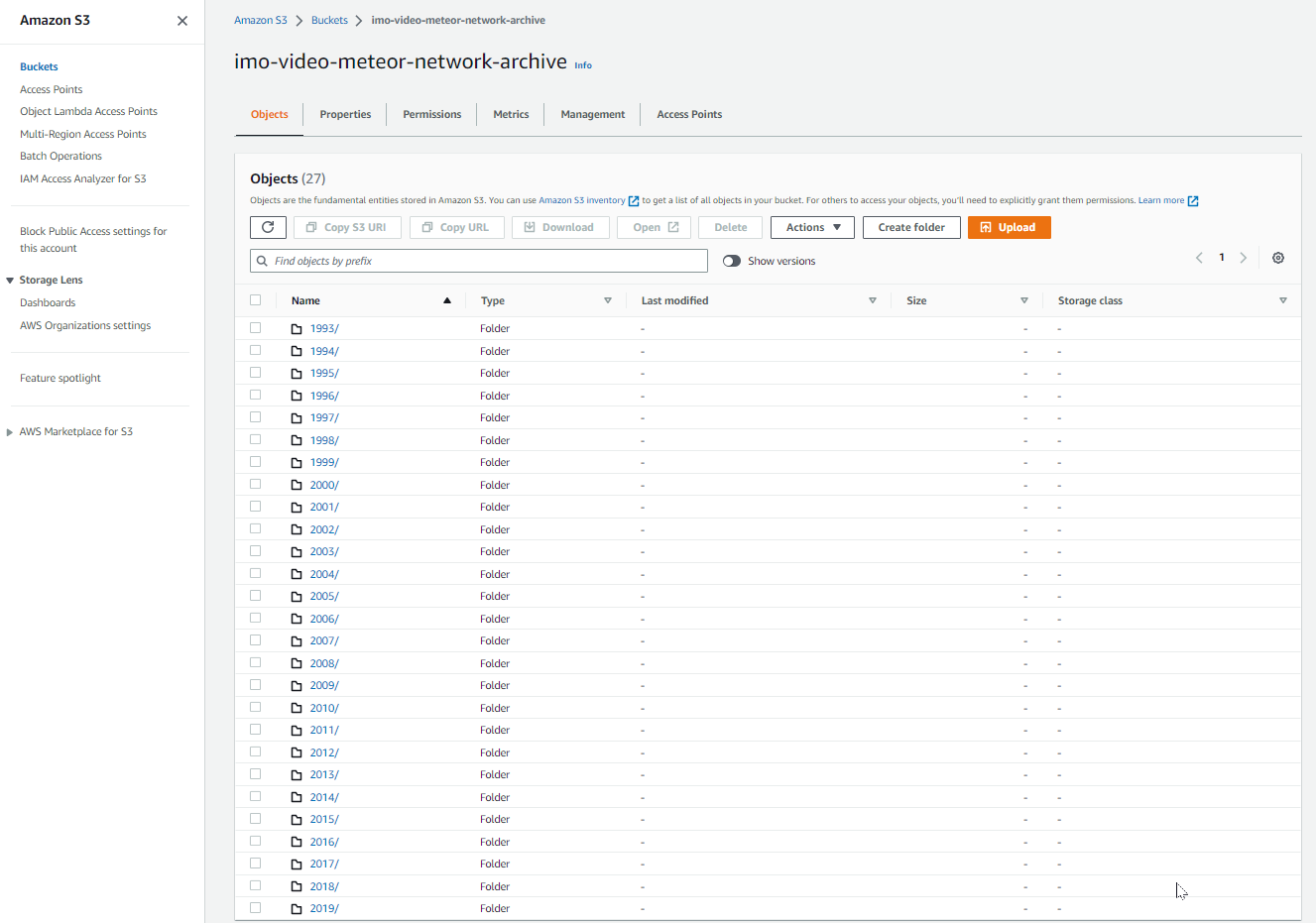
All data from a single day are compressed in one ZIP file.

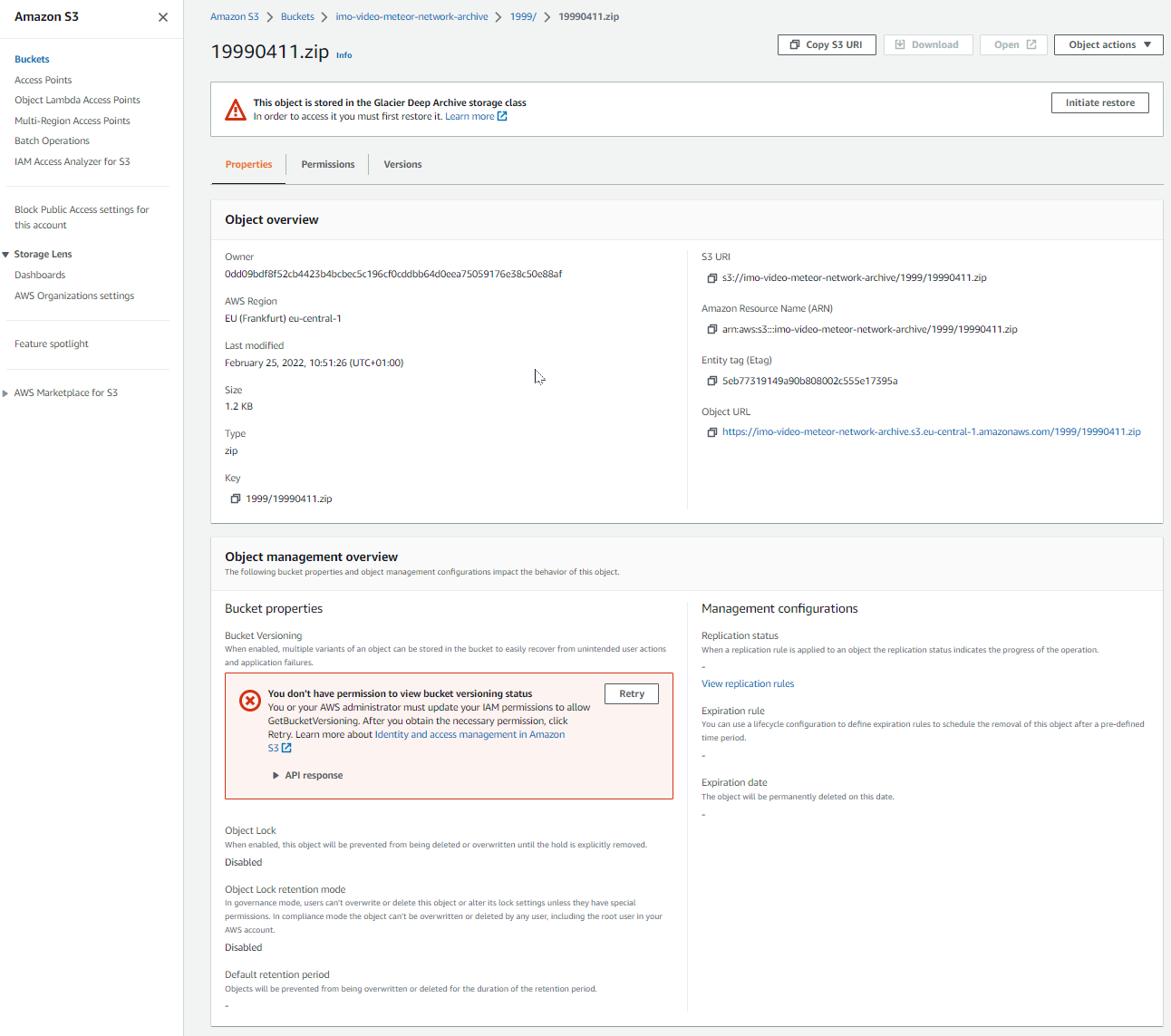
Click on the date you are interested, and you will see the file details. The Download button is inactive, as files in Glacier Deep Archive need to be restored first. This can be achieved by clicking on "Initiate Restore"
In the next screen you have to specify, how long the restored data shall be made available. As restores are charged, you should select "standard retrieval" and a reasonable duration, e.g. 14 days.
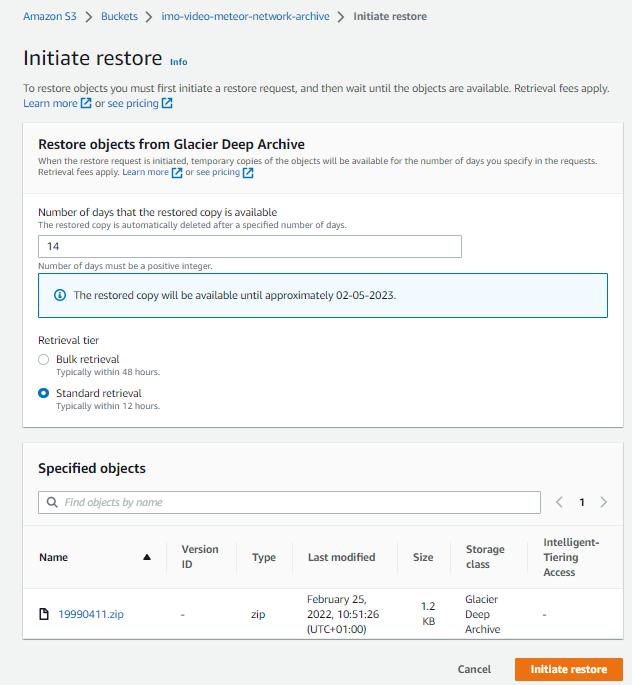
Once the restore is initiatied, you need to wait for about a days.
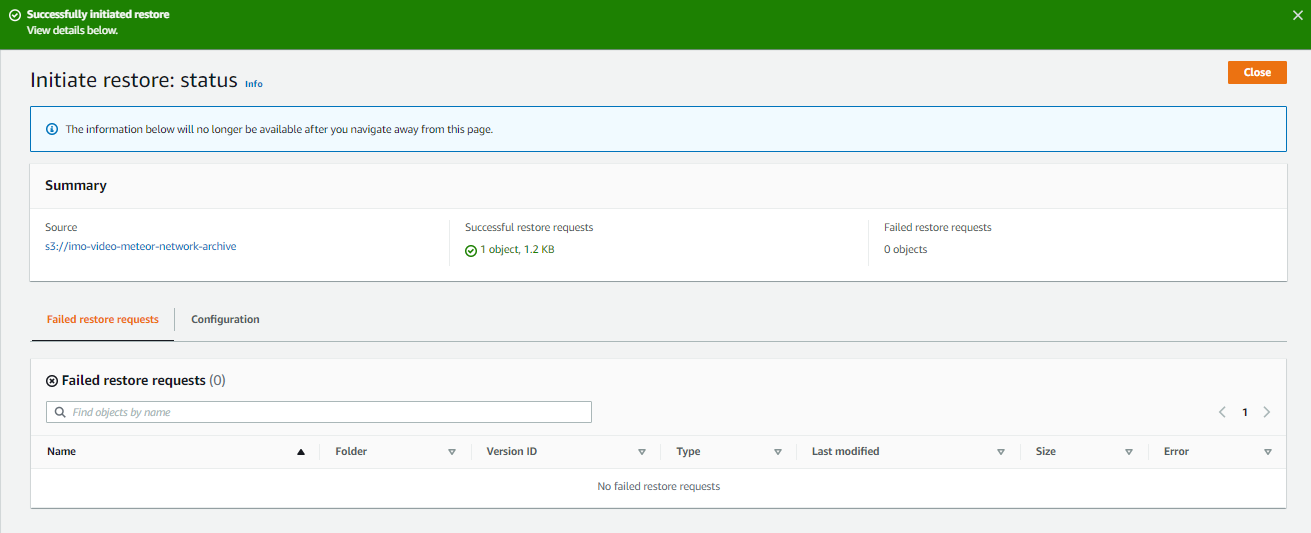
If you login the next day and browse to the same ZIP file, the download button is activated.
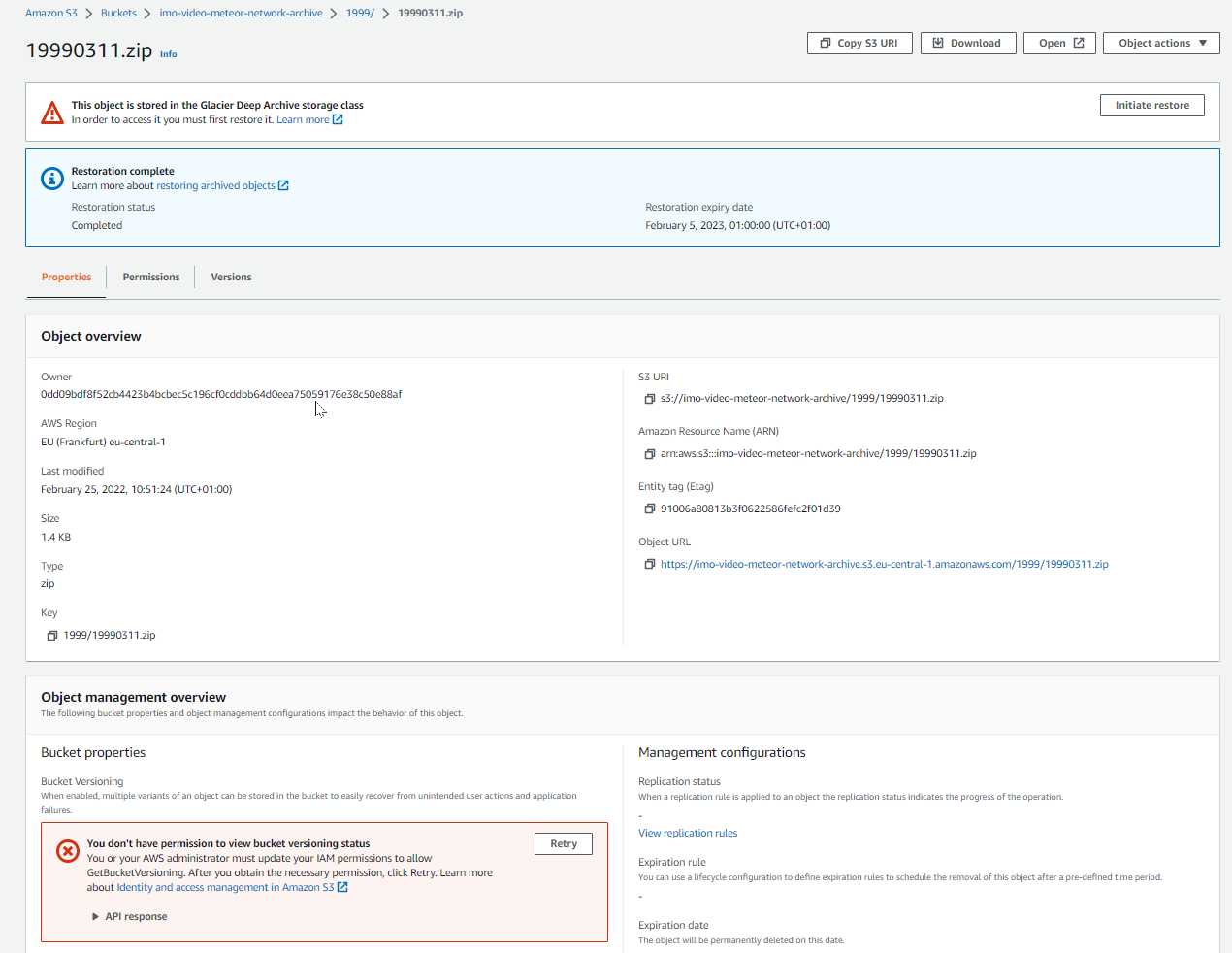
Click on it to download the files to your computer. After the specified time, the file will be deleted and another restore needs to be initiated if you want to download the file again.
If you want to downloaded several nights at once, select all relevant files and initiate the restore via the "Action" menu.
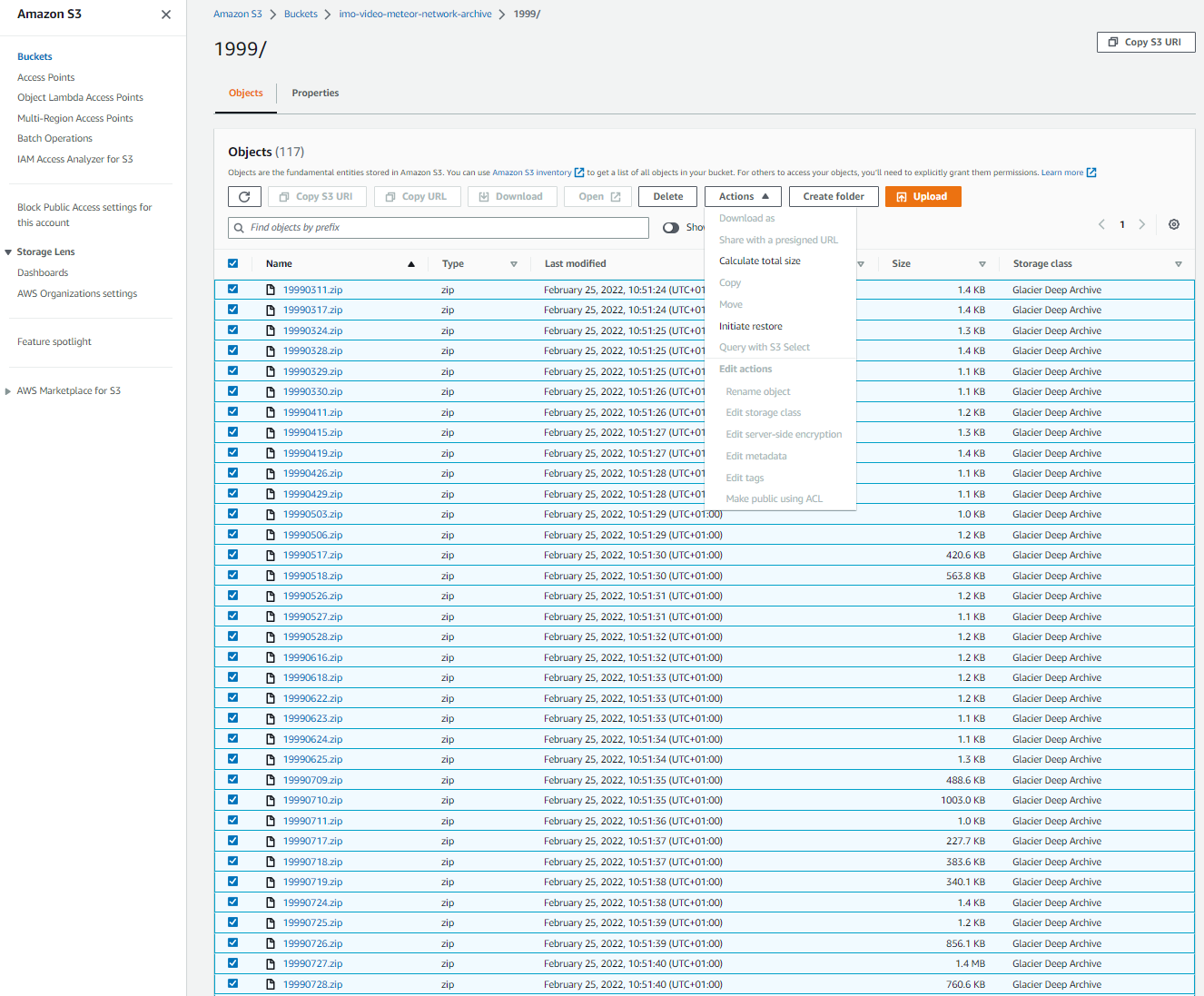
"Bulk retrieval" is the right option in this case. It takes a little longer, but it provides all data at once.
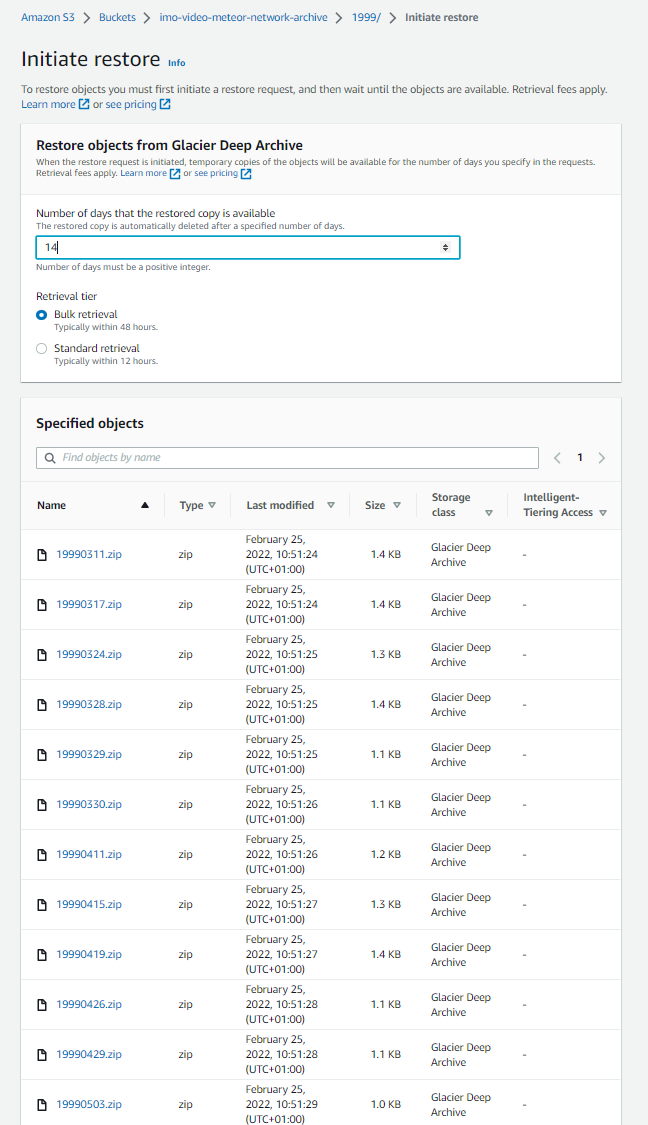
In order down download multiple files at once, you have to start the Amazon cloud shell. Sign in with the same credentials as to the S3 console.
You can then copy all or only selected restored files into the cloud shell with the aws s3 cp command, e.g. aws s3 cp --force-glacier-transfer s3://imo-video-meteor-network-archive . --recursive --exclude "*" --include "1999/199903*"

Since you cannot download multiple files to your client, you need to create a single file from all the copied files with the zip command, e.g. zip download.zip 1999*.zip
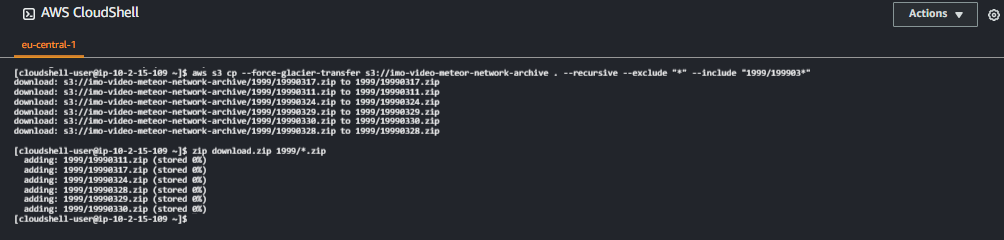
Finally you can download the files via the Actions menu

Do not forget to delete the files from the cloud shell, e.g. with rm -rf 1999 download.zip